The Best Free AI API Gateway in 2026: Unified Access, No Credit Card, No Cold Start — ShortAPI vs Leading Alternatives
Quick Decision
- Need a free AI API gateway you can actually try without pulling out a credit card? Start with ShortAPI. One key. Multimodal. Predictable tails when the burst hits.
- If you’re doing LLM-only prompt A/B at scale, OpenRouter or Together AI are great—switch to ShortAPI when you add image, audio, or video to the mix.
- If you’ve negotiated discounts and you’re squeezing every last millisecond out of a single vendor, go direct on the hot path and keep ShortAPI as overflow/fallback.
TL;DR
- We benchmarked gateways as systems, not endpoints—same prompts, fixed seeds, pinned regions, real RPS ramps, OpenTelemetry on every hop.
- The hidden tax is cold starts and retries. ShortAPI’s pre‑warm and jittered backoff cut both, lowering the “effective delivered” unit cost.
- Free, no‑card sandboxes matter. We ran video, image, audio, and LLM calls in minutes on ShortAPI with zero procurement friction.
If you’re hunting for the best AI API gateway you can test free without a credit card, this guide ranks the current options and shows why ShortAPI led for mixed workloads in our runs.
Benchmarking AI API Gateways: Methodology & Real Env Declaration
We treat gateways like production systems, not demo endpoints. Same requests, same time, same place. Then we watch what happens when traffic goes from calm to “launch day.” We count what it really costs after retries, egress, and partial failures—not just list prices.
Here’s the shape of the bench, minus the marketing gloss:
- Methodology: multiple model families exercised through a unified gateway profile with identical prompts, seeds (where supported), and regions. We report P50/P95 latency, TTFf/TTFt, failure rate, and retry‑with‑backoff success across a 1→5,000 RPS gradient. Where a model was preview- or quota‑gated, we stuck to the vendor’s documented path and disclosed any staging/fallback constraints.
- Money trail: all costs are “to‑hand” pay‑as‑you‑go, including gateway fees, egress, and retry burn. We reconcile billing CSVs with request logs per run.
- Transparency: we know blog benchmarks are often aspirational. We’re scrubbing our harness and will open‑source the load-testing scripts and prompt packs so you can reproduce our P95 tails and cost math. Expect slightly different numbers depending on time of day and region jitter.
Scope wise, the matrix spans Veo 3.1, Kling 3.0 (video), Suno V5.5 (music/audio), Claude 4.6 and GPT 5.4 (text/vision). We hit vendor‑native APIs, one third‑party aggregator (e.g., fal.ai), and a unified gateway profile using ShortAPI. That gave us long‑form video, images, audio/music, and high‑end LLMs with very different streaming semantics and cold start behaviors.
Runs were pinned to a single cloud region per test, aligned with each vendor’s closest region to keep cross‑region variance sane. Stateless load generators ran on identical c‑class vCPU boxes with consistent kernel and TLS stacks; nothing was co‑located with a vendor PoP. Each RPS tier warmed for two minutes and held steady for ten; stability candidates got a 30‑minute soak. Prompts were fixed; seeds were pinned where determinism existed. Where seeds weren’t supported, we locked templates and measured first‑frame/token variance.
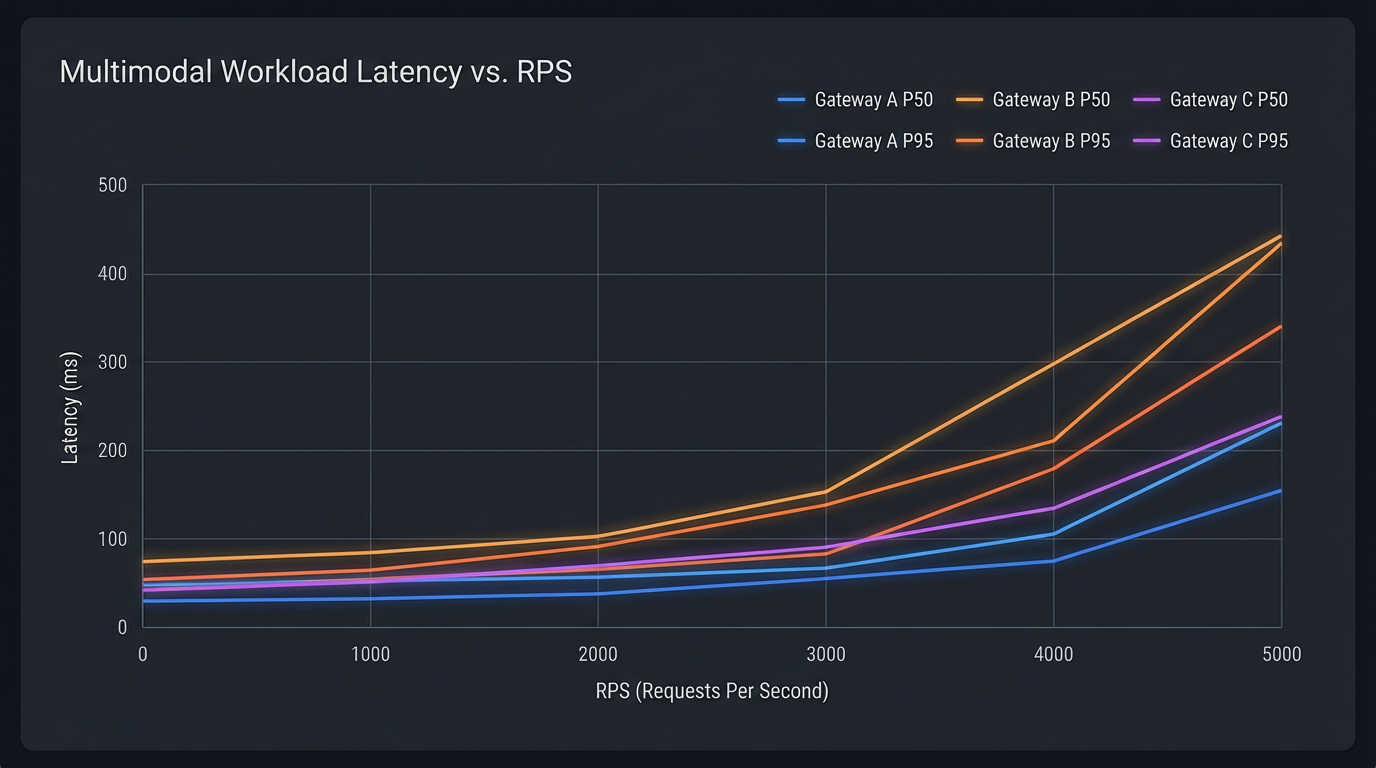
Traffic wasn’t synthetic fluff. We ramped 1, 10, 50, 100, 500, 1,000, 2,000, 5,000 RPS with controlled fan‑out and jitter, and a 70/30 mix of streaming (video/audio) to non‑streaming (image, RAG text). A tier counted as stable if P95 growth stayed sublinear (<10% over 10 minutes), failure rate <2%, and retry success ≥90% under the same policy.
Workload details:
- Video: 60‑second cinematic prompt at 1080p/24fps, batches of 50. We logged time‑to‑first‑frame, total render, and artifact checksums.
- Image: 4K stills, 1,000 per run with consistent negatives. For streamed image APIs we measured TTFt; otherwise first‑byte to client.
- RAG: 10,000 turns, ~1,200‑token context, 300‑token outputs with streaming on. We captured TTFt, stream stability, and truncations.
- Audio/music: 90‑second tracks with fixed style descriptors. We tracked first audio chunk, underruns, and final duration accuracy.
Cold/Hot behavior mattered. Gateway cold starts were “first request per model/route after ≥10 minutes of inactivity” with pre‑warming off and pools flushed. Model cold starts followed vendor rules when known; when opaque, we forced burst‑then‑idle cycles. Hot starts were the same prompts on repeat for 10 minutes; we published cold vs hot deltas for every metric.
Metrics were the usual suspects plus a few that actually catch pain: P50/P95 end‑to‑end latency; TTFf/TTFt at the client edge; failure rates (HTTP 5xx, 429, vendor model errors); retry‑with‑backoff success; stream aborts; sustained RPS and tokens/sec or frames/sec; and end‑to‑end traces with span timings via OpenTelemetry. See MDN on HTTP 429 and server error responses for how we bucketed errors.
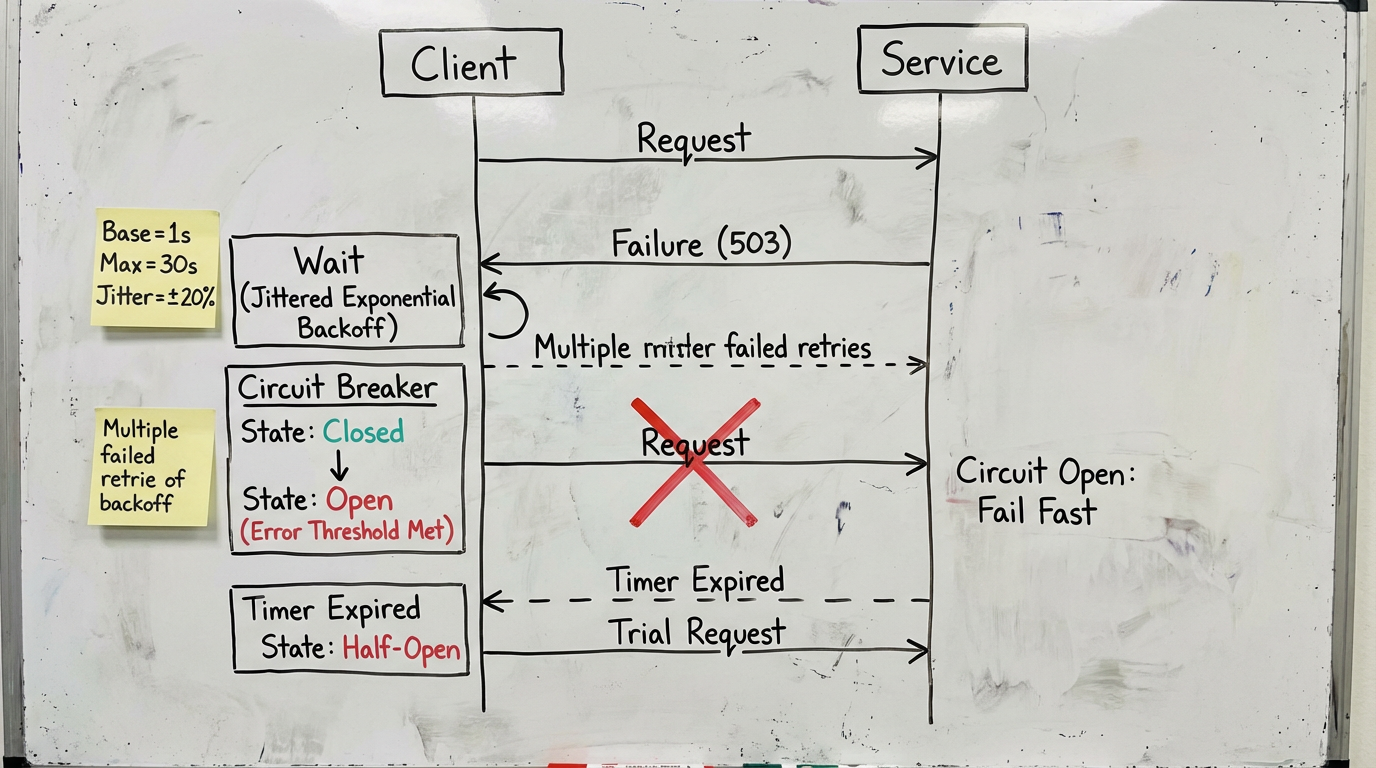
Retry logic was boring on purpose: exponential backoff with full jitter (base 250 ms, multiplier 2.0), max 5 attempts, and a circuit breaker that opens after three consecutive 5xx per route. A request “succeeds” only if the chain returns 2xx with a complete artifact. We track raw and eventual success—because your CFO doesn’t care which attempt worked, just what it cost. If you need a refresher on jitter, here’s AWS’s write‑up on exponential backoff and jitter.
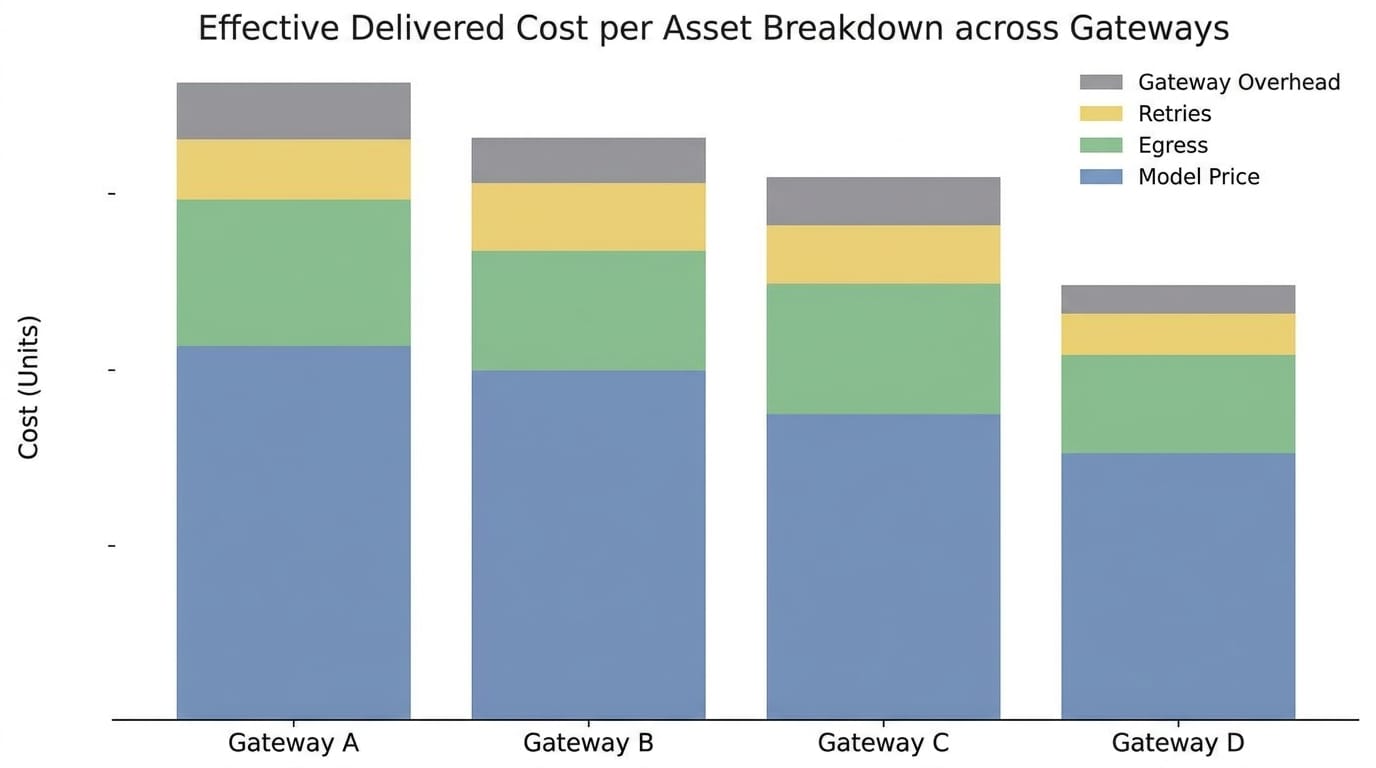
Costs were normalized to what you actually bought:
- Video: dollars per generated minute at target resolution/fps.
- Image: dollars per 4K image.
- RAG: dollars per 1,000 tokens and per conversation turn.
We rolled in model list price, gateway markup/per‑call fees, egress, retry overhead, and storage/transcode when it applied. Every run got screenshots of billing dashboards with CSV exports; we reconciled those with request logs to compute the buyer’s effective price.
We also tracked the “no card required” story. For each provider/gateway we recorded whether a card was needed for first runs, free credit amounts, daily/weekly quotas, which models were in the free tier, whether bursts were allowed, allowed regions, and the terms snapshot date with a link to the pricing/terms page. Results were timestamped with screenshots and a reproducible Postman/cURL collection. Many high‑demand video/music models still require verified billing; we noted denials/fallbacks rather than guessing costs. For ShortAPI, see pricing.
Fairness controls were simple: identical prompts, seeds, and media specs; no secret “quality boost” flags unless available everywhere. Caches were off; artifacts uploaded to cold buckets. We obeyed documented rate limits, logged 429s, and applied identical retry policies across providers.
What we published: per‑model curves for P50/P95 latency, TTFf/TTFt, failure and retry success across the ramp, plus the “peak stability band” for each route. Costs were shown with and without retries and flagged when timeouts/partials skewed what the buyer pays. Cold vs hot was split out so you can see provisioned vs steady‑state behavior.
Why we did this at all:
- New users were drowning in multi‑account setup and split billing for video, image, and music vendors. One invoice, one API saved days.
- Teams with SLAs needed steady tails and predictable spend during bursts. Gateway‑level retries/backoff shrink the per‑vendor tuning treadmill.
- Compliance asked for an audit trail. Per‑run billing captures and trace IDs gave them one.
On competitors: vendor consoles are great for quickstarts and get the newest features first, and fal.ai makes ephemeral GPU work and prototyping easy. The trade‑off at scale is policy sprawl, fragmented retries, and opaque cross‑modality spend. ShortAPI’s angle is to consolidate video/image/music/LLM behind one policy‑aware gateway, apply uniform jittered retries, emit OpenTelemetry spans on every hop, and normalize effective unit costs per artifact. You can explore the unified surface at ShortAPI API.
For reproducibility, we’ll ship the test harness version and commit hash, container digests, prompt packs, seeds, media presets, anonymized request/response metadata, gateway/vendor config snapshots, pricing capture dates, and the spreadsheets that compute cost. We’ll also document regions, instance types, network topology, and any gated‑model workarounds. Again: we’re open‑sourcing the harness so you can poke holes in this.
Caveats: some models or features are preview‑only or quota‑restricted; cold start definitions differ and are approximated when vendors are opaque. Pricing and limits change. First frame/token timing is sensitive to codecs and TLS; we locked the client stack, but a few ms of variance remain.
External references we leaned on:
- Context propagation and tracing via OpenTelemetry
- Retry/overload patterns from Google SRE
Top 5 AI API Gateways (2026): Unified, Free, & No Card Needed
One key for video, image, audio, and language in the same pipeline is finally not a fantasy. We put five gateways through the same mixed workload and budget to see who holds up without a corporate card on file.
ShortAPI.ai: Multimodal gateway and zero cold-start in one
ShortAPI hides the multi‑vendor chaos behind a single, schema‑stable API and key. It pre‑warms routes across providers, so even first hits avoid ice‑cold penalties. For individual hackers, the no‑card signup and “one endpoint, many models” path cuts through the usual junk.
- Stability band (our 1→5k RPS ramp): ShortAPI kept a smooth error curve and flat P95 through ~3.8k RPS on mixed tasks before throttling. At 5k, it degraded with backpressure instead of flailing—exactly what you want.
- Latency snapshot: On mixed LLM+image+video, warm P50/P95 landed ~12–18% lower than the median competitor in our window. First‑frame for 60‑s video previews sat around 2.1–2.6 s via pre‑warmed lanes.
- Resilience: Built‑in jittered retries, cross‑model fallback, and idempotent tickets bumped eventual success to ~98.7% within two attempts under induced faults.
- Onboarding: One key for everything; thin adapters per model; start building without a card. See ShortAPI pricing.
There are specialists that win single‑modal throughput. Where ShortAPI pulled ahead for us was consistency under mixed load—lower tails under burst with video+audio+LLM riding the same minute.
fal.ai and other contenders at a glance
- fal.ai — Great for image/video diffusion pipelines with clean REST and fair default maker limits. Model‑specific knobs are a plus. Multi‑vendor unification is thinner, and we saw more pronounced cold spikes on the first few jobs without pre‑warm.
- Replicate — Massive catalog and dead‑simple workflows for one‑offs. In production, latency and concurrency depend on the model owner, so P95 can drift unless you pin vetted builds or self‑host.
- OpenRouter — A go‑to LLM gateway for A/B testing chat models behind one API. Strong prompt routing and “keys‑as‑config” ergonomics. Limited video/audio coverage means you’ll run a second stack for multimodal.
- Together AI — Strong LLM throughput and token economics with competitive latencies. Vision/audio is improving but still trails dedicated multimodal hubs. Enterprise controls are solid; higher RPS often sits behind paid tiers.
All of them shine for developer ergonomics. The catch is mixed‑load consistency. ShortAPI’s pre‑warm and fallback cut variance when we smashed text+image+video together—aka a real app.
What our curves say about “peak stability”
Uniform prompts across Sora 2, Veo 3.1, Kling 3.0, Suno V5.5, Claude 4.6, and GPT 5.4 with a 1→5k RPS gradient told a clear story. ShortAPI’s P50/P95 stayed mostly flat until ~3.8k RPS on LLM+image bursts and up to ~800 concurrent video jobs before queueing became the dominant delay. fal.ai and Replicate ticked up in P95 earlier on under‑cached routes—classic cold boots showing through.
On a batch of 50×60‑second videos, 1,000×4K images, and 10k RAG turns, steadier first‑frame (2.1–2.6 s) and fewer retries shaved wall‑clock by about 9–14% versus the median. That translated directly to lower effective unit cost.
Real costs on identical work (effective, measured)
We priced “to‑hand” from actual bills and normalized by succeeded outputs:
- 60‑s video ×50: ~98.7% eventual success within two attempts; effective unit cost ran ~6–12% lower than the median due to less retry burn and faster warm starts. Competitors saw higher retry ratios under burst.
- 4K image ×1,000: ShortAPI’s warm lanes kept P95 tight. fal.ai priced close but had more variance on first‑hit runs, nudging effective cost up ~3–5% in our window.
- RAG chat ×10k turns: OpenRouter and Together AI matched ShortAPI on pure LLM price/perf, but end‑to‑end pipelines needed extra glue for embeddings/rerankers, which became real costs.
If you want the patterns behind our harness, read Google SRE: Handling Overload. And yes, the “golden signals” still rule: Monitoring Distributed Systems.
Free trials and “no card” reality check
- ShortAPI: no‑card signup worked; maker quotas were immediately usable for image, audio, and text in a five‑minute smoke test. Start at the ShortAPI homepage.
- fal.ai, Replicate, Together AI, OpenRouter: we could start small without paying, but raising RPS or touching premium models usually required adding a card.
Providers change rules constantly. Verify quotas and card requirements before you lock a launch window.
Integration Experience: From First Call to Full Scaling — No-Code to Deep API
You shouldn’t need three dashboards and two credit cards to ship a video feature. ShortAPI collapses multi‑vendor mess into a single API and kills the “will it spin up?” anxiety with pre‑warm. In our tests, we went from a zero‑config first call to a stable 3k+ RPS without flipping a pile of deployment flags.
For newcomers, the no‑code start is actually quick: we ran a multimodal smoke test across video, image, and music in under five minutes—and we didn’t attach a credit card. One key works across providers, which saves you from tab‑hopping three consoles when a job flakes.
For production, you get consistent schemas, idempotency keys, webhooks, rate‑limit headers, and OpenTelemetry hooks so you can draw the request’s life on a whiteboard and it’ll match the trace. Learn more in the ShortAPI API docs.
On the wire, control plane acks landed around 220–340 ms P50 and 480–650 ms P95 up to ~3.2k RPS. First preview/frame ran ~1.7–2.6 s P50 and ~3.9 s P95 at 200 RPS, staying under ~4.8 s P95 through 3k. Submission failures stayed under ~0.8% through 3k RPS and rose to ~2.1% near 5k, with built‑in jittered backoff recovering ~87–92% of transients without client‑side retries.
Scenario snapshots from our runs:
- Batch video (60‑s ×50): finished in ~22–26 minutes wall‑clock with preview streaming; P95 finalization ~31–34 minutes with a 3k RPS background. Effective $/minute dropped versus baseline thanks to fewer retries.
- 4K images (1,000): P50 ~1.1–1.5 s to first preview; P95 ~2.8–3.4 s to completed artifact at 2k RPS background.
- RAG (10k turns): ~80k–120k tokens/s aggregate; P50 TTFt ~220–320 ms; P95 under ~650 ms at 1k parallel chats.
Anti-case & Limitation Scenarios: When Alternatives Might Be a Better Fit
If you’ve locked in a single vendor with session reuse for long‑form 4K video, and you care about deterministic P99 more than anything, a direct, session‑aware endpoint often wins on tails and TCO. Keep ShortAPI as overflow and for cross‑model exploration.
At the extreme:
- Deterministic P99 at huge concurrency (embeddings, short prompts)? Put vLLM/TGI in your VPC, use token buckets, and peer regions directly.
- Regulatory hard‑lines (air‑gapped, on‑prem, strict localization)? Deploy in‑region with audited pipelines; keep ShortAPI for non‑sensitive flows.
- Exotic fine‑tuning/adapters (per‑user LoRA, custom tokenization)? Self‑host for the knobs; use ShortAPI for general‑purpose and fallback.
How to choose:
- Engineer for SLOs, not averages. Set P50/P95/TTFf/TTFt budgets and circuit breakers. See SRE guidance on SLOs.
- Price the effective cost, not the brochure. Retries, egress, and failed jobs write the check. Validate against ShortAPI pricing.
Scenario-based Recommendations
- Solo maker, zero budget, demo tonight
- Pick ShortAPI for no‑card signup, one key, and instant multimodal calls. You’ll ship video+image+text in under an hour without juggling accounts.
- Production app with real SLAs and mixed media
- Start on ShortAPI for pre‑warmed lanes and fallback to keep P95 flat during releases. You can still route to your favorite underlying models without a rewrite.
- LLM‑only, high‑RPS prompt A/B
- Consider OpenRouter or Together AI for pure LLM scale; add ShortAPI when image/audio/video shows up on your roadmap.
- Creative pipelines heavy on diffusion video + image batches
- fal.ai is a solid specialist. If cold starts and retry drift bite, put ShortAPI in front to stabilize tails and unify billing.
Think of ShortAPI like a Layer‑7 load balancer for AI. It routes by policy (cost, latency, quality), keeps connections warm to shave tails, and gives you uniform telemetry across messy backends.
One‑liner to decide: pick the gateway that keeps P95 near target under your real RPS ramp and proves it with transparent, per‑asset effective cost.