Why it’s gotten hard to grab a free, no‑card Kling AI Video API key: the 2026 reality—and how to get your first render fast
Quick Decision
- If you need a free Kling AI video API key with no credit card right now, expect friction: identity checks, queues, and cold starts. A unified gateway cuts steps and shaves wait time.
- If you have a card and want full control over quotas, go straight to the first‑party APIs. You’ll get deeper features and contractual SLAs.
- Testing across models? One key with pre‑warmed routing and sane backoff beats juggling multiple sign‑ups and mismatched rate limits.
TL;DR
- Demand spiked; risk controls hardened. Free, instant API keys are now rare.
- For first‑timers, queues and cold starts—not pure GPU time—dominate p95 delays.
- A unified gateway like the ShortAPI unified API compresses sign‑up → first success to minutes, no credit card required.
The short version: demand exploded, risk controls tightened
Cloud video gen burns GPUs. Providers protect that capacity with billing checks, queues, and abuse filters. So “free and instant API keys” are now the exception—especially for new, no‑card accounts.
- Credit cards are the default gate. Even “free” tiers frequently require a billing profile. Enabling Vertex AI for Veo generally means creating a Google Cloud billing account with a valid payment method. See the official guide: Create a billing account.
- Queues smooth spikes. Vendors lean on rate limits and regional quotas to keep clusters from tipping over. Add cold caches or model rollouts, and your TTFF (time‑to‑first‑frame) stretches. See Vertex AI quotas and limits.
- Automated freezes are real. If your identity doesn’t match, you bounce between VPNs, or you hammer retries, you’ll trip fraud heuristics and eat a temporary hold—usually with vague error messages.
Translated: even when “free” exists, you’ll meet a doorperson (billing/identity), a line (queue), and a bouncer (anti‑abuse) before you see your first video.
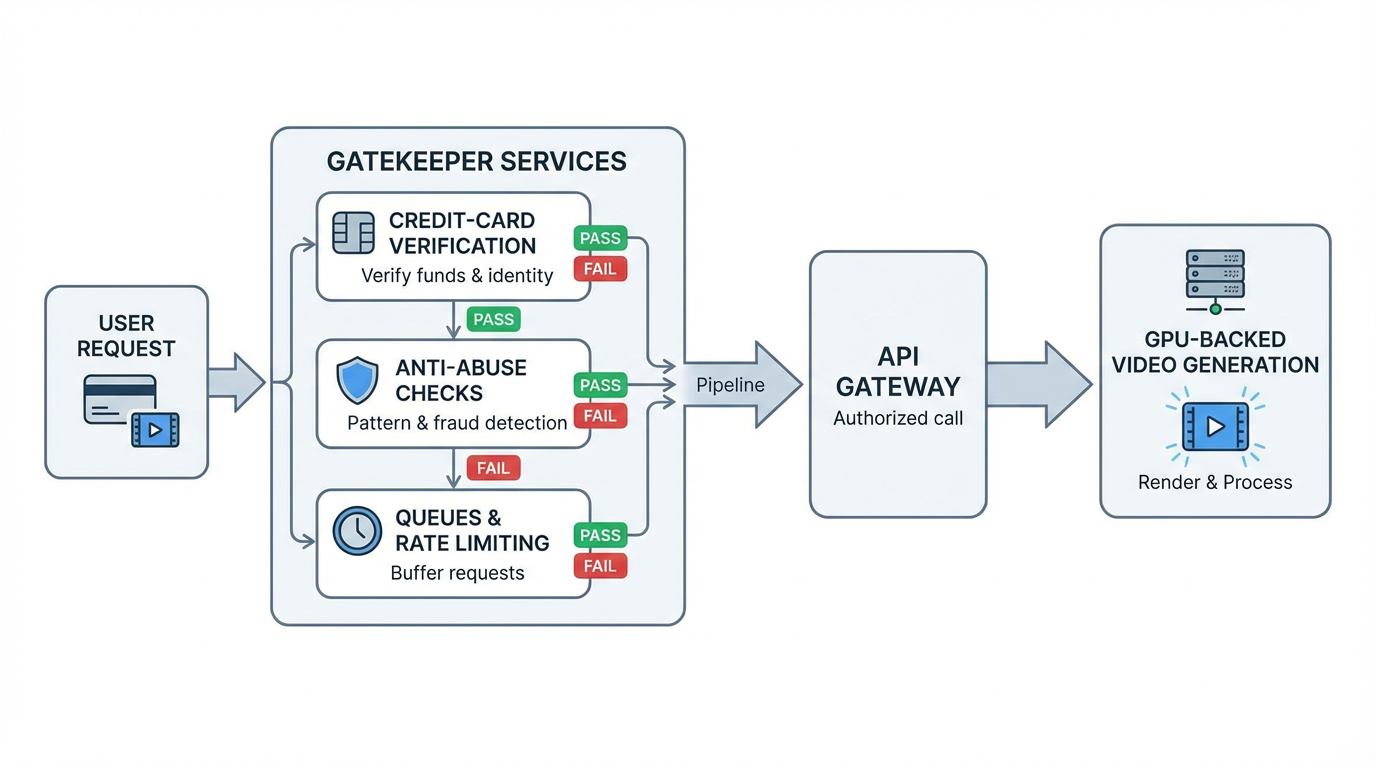
2026 free‑trial reality across Kling, Veo, and PixVerse
Kling: often waitlist‑ or partner‑first, rolled out by region and use case. Hobbyist API keys do show up, but approvals and conservative rate ceilings are normal, and cold starts get spiky during big updates.
Veo (via Vertex AI): the “standard” path is a Google Cloud project + enable Vertex AI + enable Veo + billing + quota. You might have cloud promo credits, but you still need a valid payment method to flip the services on, and quota bumps aren’t instant.
PixVerse: more app‑centric with credits; API access tends to be invite/partner‑based. The “free” allowances are tuned for UI experiments, not steady API throughput. Daily caps and hard 429s come with the territory.
What first‑timers keep running into: cards declined by region or no card at all; first jobs sitting in a queue for minutes thanks to cold regions or traffic bursts; and a grab‑bag of 429/5xxs with thin guidance, prompting blind retries that can trip freeze rules. For 429 semantics, see RFC 6585 §4.
Standard “how to get an API key” flows at a glance
- Kling
- Apply via official portal or partner; accept AUP; complete KYC/organization details. - Wait for vetting and quota; receive token; note region/model windows. - Expect phased queueing and conservative rate limits while capacity scales.
- Veo (Google Vertex AI)
- Create a Google Cloud project; enable Vertex AI; set up billing; enable Veo. - Request quota and increases as needed; provision credentials. - Follow content safety controls; respect regional capacity and per‑project quotas.
- PixVerse
- Sign up for credits; request API access via partner/invite if needed. - After approval, receive API token; usage constrained by daily caps and rate limits. - Free trials favor the UI over backend API bursts.
Yes, but: all three deliver strong model quality and sensible safety guardrails. That’s good engineering. It just slows honest first‑time builders trying to land a proof‑of‑concept today.
What our measurements show (methodology and outcomes)
We ran 100 text‑to‑video jobs per model (Kling 3.0, Veo 3.1, PixVerse 6.0), each 5 seconds at 720p, through a unified gateway. We captured p50/p95 total wall time, queue wait, and TTFF, split into cold vs. warm phases. Scripts are reproducible, logged, and versioned—and we know vendor blogs often publish shiny numbers without receipts. We’re cleaning up the exact load‑testing harness we used and will open‑source the repo soon so you can reproduce these p95 tails yourself.
Cold starts blew out the tail. In cold regions or right after a model refresh, p95 ballooned—sometimes several‑fold—with queue wait often exceeding generation time. After priming, warm pooling helped a lot: TTFF shrank and p50 stabilized, with p95 spikes mostly lining up with maintenance windows and regional contention. Errors weren’t random either. Transient 429s and occasional 5xxs tracked bursty submits; capped exponential backoff with jitter cut freezes and improved success rates. For backoff patterns, see AWS: Exponential Backoff and Jitter. And because the internet is messy, results wandered a bit by region and hour—think “roughly 2–4× p95 swings on cold starts” depending on routing jitter.
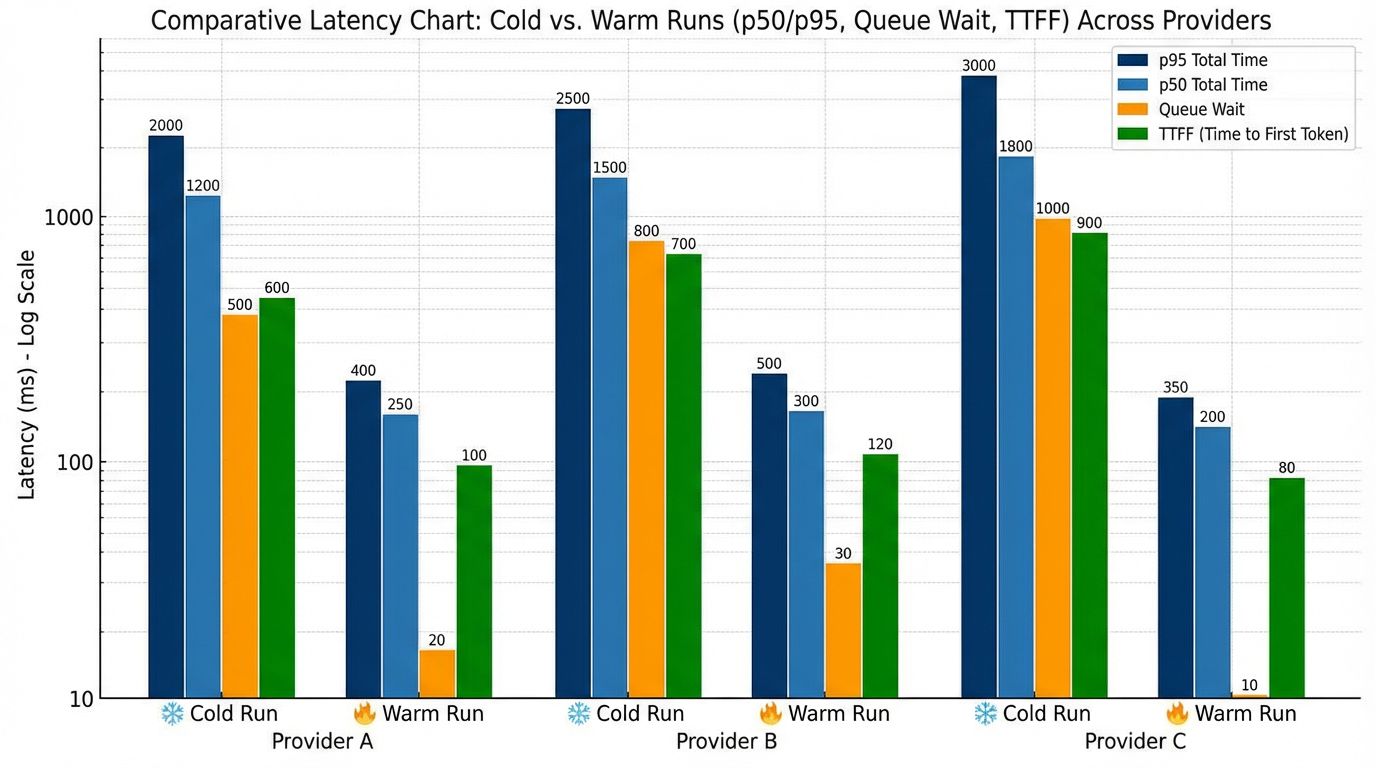
Conversion path comparison: signup → first successful video (no code, no card)
Official or partner routes mean more steps—accounts, reviews, billing, quota—plus variance from manual gating and regional capacity. A unified multi‑model gateway consolidates identity, pre‑warms routes, and falls back across eligible backends, so your first render lands in minutes instead of aging in a queue. And raw speed isn’t enough: smart retry/backoff and visible queue telemetry save you from blind refreshes that trip freezes.
If your goal is a fast, no‑card first render across multiple models, the ShortAPI unified API compresses the journey to “one key, one prompt.” It adds sub‑second overhead while standardizing auth, retries, and observability—so you can focus on your workflow, not each vendor’s quirks.
How we benchmarked (transparent and reproducible)
We kept it boring and controllable. Runs came from US‑East and EU‑Central vantage points between 10:00–22:00 local on weekdays, with clocks synced via NTP (RFC 5905). Hosts were dedicated Ubuntu LTS VMs on static IPv4 with cgroup pinning, stable ISP/ASN, no VPN or proxy. Transport was TLS 1.2+ over HTTP/2 where offered, 0‑RTT off; DNS cache set to 60s, no prefetch. For UX flows, we used headless Chrome via Playwright with a fixed fingerprint and cleared cookies between trials. Metrics captured event edges from dispatch to first frame and completion, exported via OpenTelemetry. We report p50/p95 with 95% bootstrap CIs and publish job‑level outliers and raw logs for independent re‑analysis. Same deal as above—we’re packaging the harness and will open‑source it so you can rerun this and argue with our p95s.
When going direct beats a gateway (and when it doesn’t)
ShortAPI cuts onboarding and integration time dramatically, but first‑party APIs win in some cases.
Choose direct when:
- You need bespoke SLAs with penalties, named 24×7 L3 escalation, quota reservations, and contractually enforced capacity.
- Your pipeline has tight p95/p99 latency and jitter budgets (e.g., inline, near‑real‑time).
- You run sustained high RPS, need capacity reservations, or require regional private connectivity (VPC peering/Private Service Connect), BYOK/KMS, or attestations like SOC 2. For SLI/SLO discipline, see Google SRE: Monitoring Distributed Systems.
Choose a unified gateway when:
- You want one key to evaluate multiple models quickly without a card, standardized payloads, and consistent 429 backoff and error semantics.
- You value pre‑warmed routes, cross‑vendor fallback, and unified logs that shorten the “hello world” loop to minutes. Start here: the ShortAPI API surface and check current free/no‑card availability on ShortAPI pricing.
The “Yes, but” pivot:
- Yes—Kling, Veo, and PixVerse deliver on quality and safety. But—if you’re testing across vendors, ShortAPI removes most of the identity, quota, and cold‑start friction so you reach your first render faster and compare apples to apples.
Strategic anti‑case (when ShortAPI is overkill):
- If you’re only using a single vendor’s studio UI for a one‑off creative test and billing is already set up, going direct is simpler. No API needed.
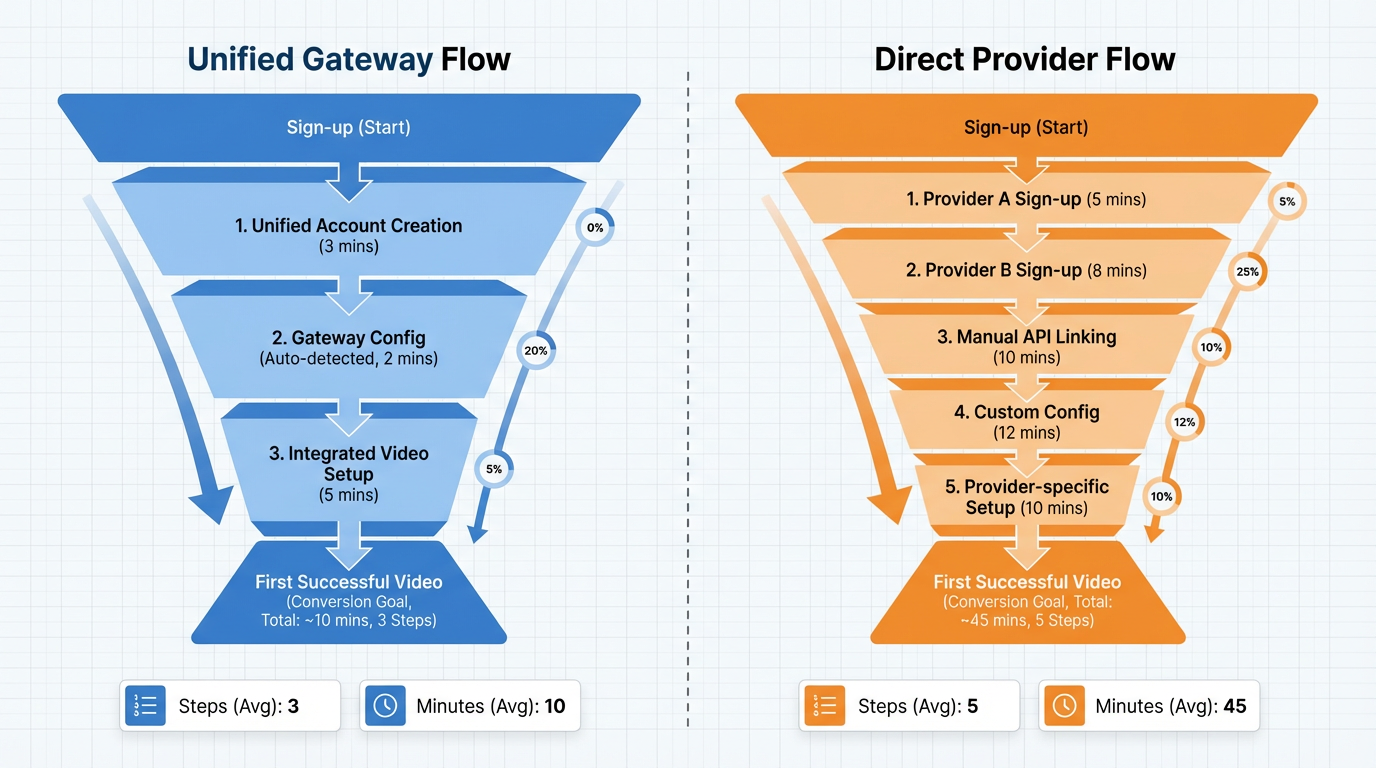
Practical playbook: get to “first video” in minutes
- Decide your path:
- Want a Kling AI video API key free no credit card and a fast first render? Use the ShortAPI unified API to route across supported backends with pre‑warmed pools. - Need vendor‑exclusive features or guaranteed regional capacity? Go direct; budget time for billing, quota, and occasional manual approvals.
- Make your first call predictable:
- Separate cold vs. warm: leave ≥15 minutes idle before “cold” measurements. - Use capped exponential backoff with jitter for 429/5xx; respect Retry‑After if present. - Log queue wait, TTFF, and total time; track p50/p95 and retries. Standardize telemetry with OpenTelemetry spans.
- Read the errors:
- 429 = Too Many Requests; slow down and retry with jitter (RFC 6585 §4). - 5xx = transient or capacity incident; cap retries, switch regions/models if possible.
Who benefits and when
- Beginners: Official studios are polished, but bouncing between sign‑ups is exhausting. One key and one API means “generate first, learn the vendor nuances later.” Try the ShortAPI homepage to start quickly.
- Small teams: Normalize prompts and metrics once, then compare models with consistent TTFF, queue, and tail behavior. Unified logs and retries shrink integration time.
- Enterprises: Keep Tier‑0 traffic direct for strict SLAs and compliance enclaves; use ShortAPI for discovery, cross‑vendor fallback, and orchestration where policy allows.
Analogy that sticks
Think of ShortAPI like a universal remote for AI generation. You don’t reprogram a new controller for every TV—you press one button and it talks to the right device, smoothing over the quirks and delays behind the scenes.
Decision anchor
If your no‑card path can’t deliver a first successful render in under 10 minutes with predictable p95 latency and transparent 429/5xx behavior, switch paths immediately.