2026 AI Image APIs: Free, Fast, and No Credit Card—What Developers Really Need
If you’re hunting for an AI image API that’s free to start and hands you an API key without a credit card, here’s the unglamorous truth: demos fail because of friction and tail latency, not because the model isn’t “good enough.” In 2026, the only clocks that matter are time-to-first-image and time-to-scale. Across our runs, removing card walls and cold starts consistently shipped more demos than swapping in yet another “best model.”
Quick Decision
- Spinning up a prototype today? Use a gateway that gives you instant keys and has warmed edges. If day-one is gated behind billing/KYC, you’re losing the morning.
- Planning to burst? Look at P95 under load and whether the vendor actually shows queue time. If they hide tails, assume pain when you present.
- Expect to swap models? A single key with a unified API beats juggling three SDKs and their rate limits.
TL;DR
- Friction kills prototypes faster than model choice. Instant keys, no credit card, and a unified schema get your first image in minutes.
- Users feel tail latency, not your P50. Warm pools, edge routing, and sane backoff discipline matter more than a pretty median.
- Consolidated quotas and billing keep ops and finance sane; go direct only when a provider’s feature or reserved rate is your moat.
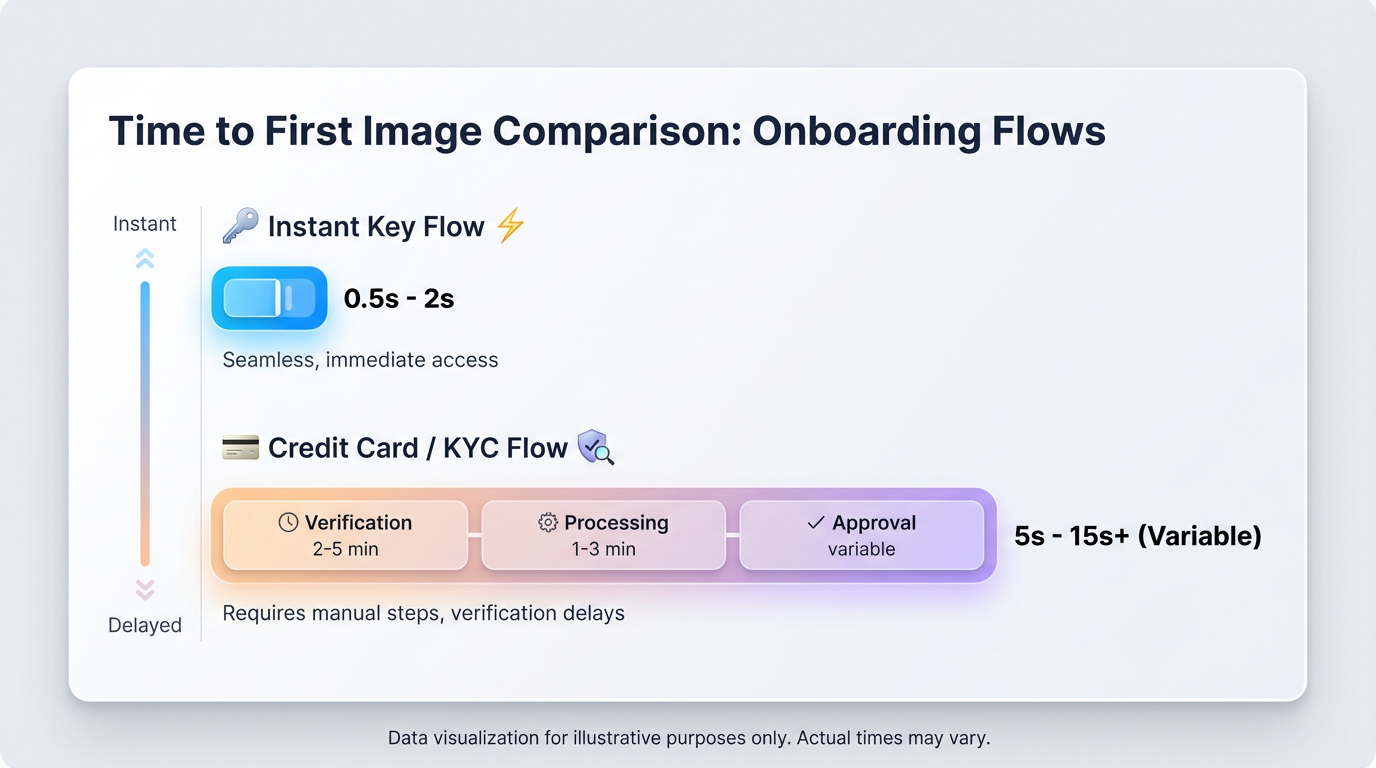
Why free, no-card, instant API keys are now non‑negotiable
If you’re prototyping, card/KYC gates can drag time-to-first-image (TTFI) from minutes to days. That’s how hackathons, classes, and POCs stall out. You’ll also model-hop—Seedream 5.0, Nano Banana Pro, Midjourney V7, Flux 1.0—in hours, not weeks. Fragmented credits and incompatible schemas become a tax. One key, one schema, and clear free-tier limits let you validate UX today. If you want a unified start, the ShortAPI surface is here: ShortAPI API.
If you’re on an enterprise track, you care about measurable P50/P95, consistent success rates, rate limits that don’t surprise you, and real burst capacity. You need observability and SLA coverage that maps to your regions, and you want sane TCO rather than glossy dashboards. The Google SRE “golden signals” remain a solid lens: Monitoring Distributed Systems.
In plain English: shipping fast depends on two clocks—how quickly you can create the first image (TTFI) and how well your P95 holds when traffic spikes. The first gets blocked by signup forms and key delays; the second gets torched by cold starts and queues.
For background on cold starts in today’s serverless stacks, see AWS’s notes on Lambda execution environments and tuning tips in their compute optimization notes. For why tails dominate user experience when systems fan out and retry, read Google’s “The Tail at Scale” paper.
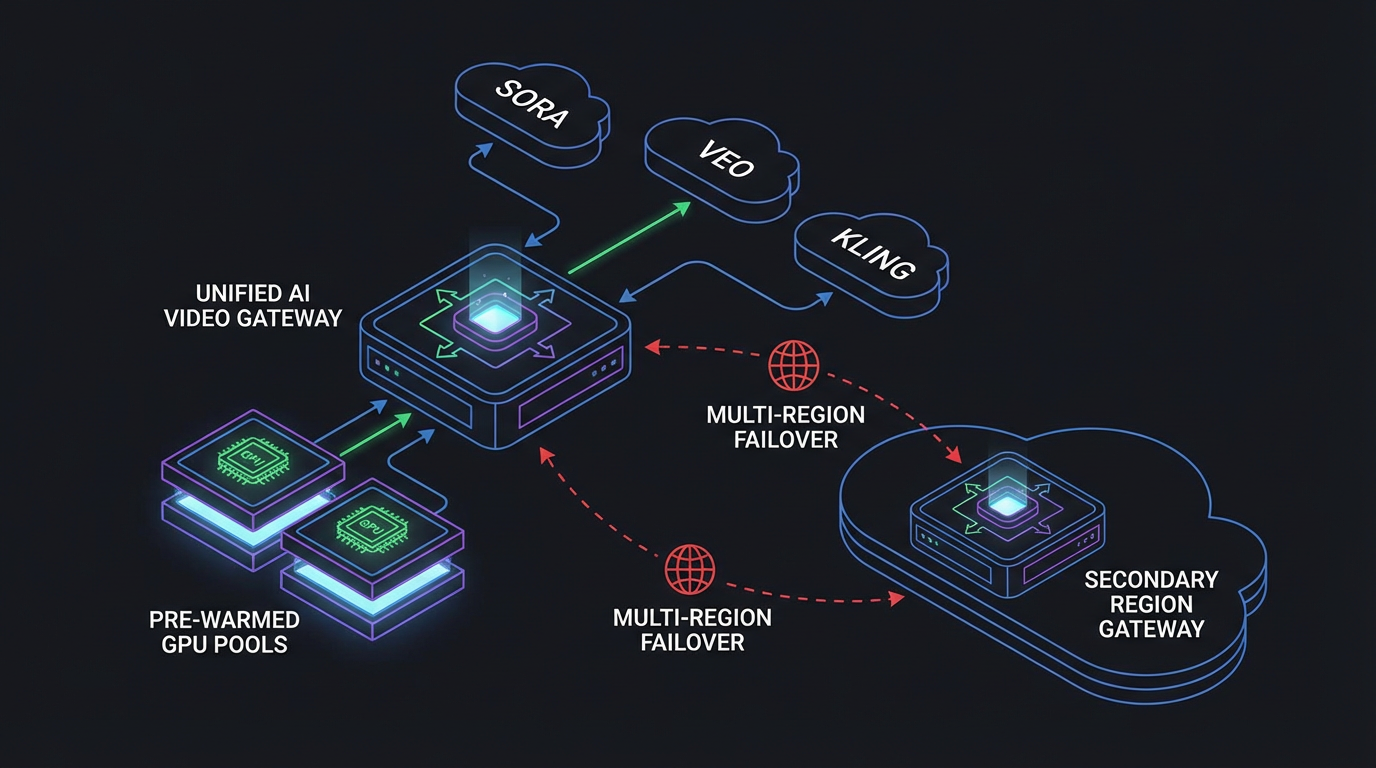
Where the platforms differ (and where ShortAPI sits)
Provider-native “foundation” APIs are steady and high quality, but they come with account overhead and implicit lock-in. Hosted open-source gives you flexibility (Stable Diffusion variants, Flux 1.0), but schemas and P95 can swing under load. Aggregators and gateways trade some control for unified APIs, routing, and failover; in return, you get consistent QoS and observability. Rolling your own (Kubernetes + vLLM/Comfy/A1111) buys control at the cost of capacity planning, autoscaling, and living with cold starts.
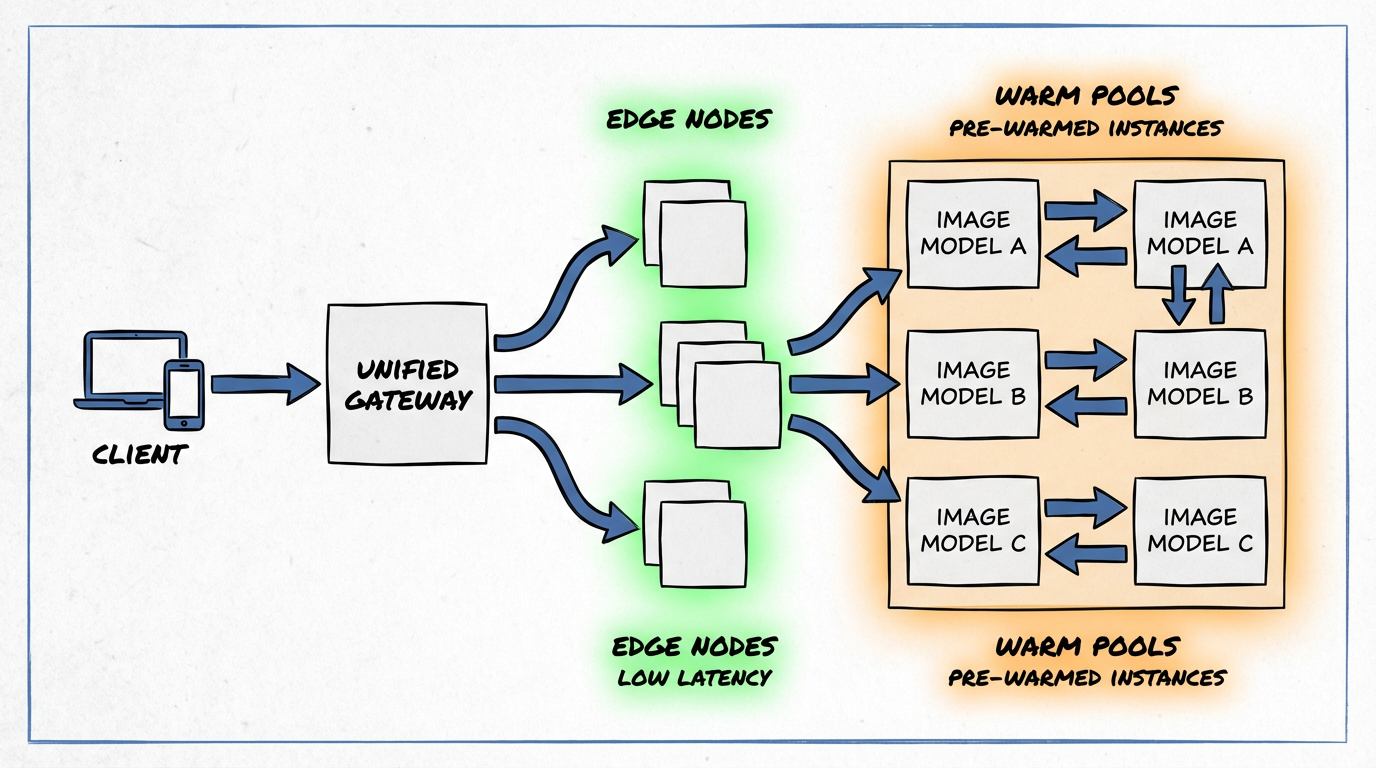
ShortAPI’s posture: a multimodal gateway that issues instant API keys (no credit card), normalizes schemas across image/video/audio, and keeps warm regional pools to smooth P50/P95 and absorb spikes. If you want to see the surface, start here: ShortAPI API.
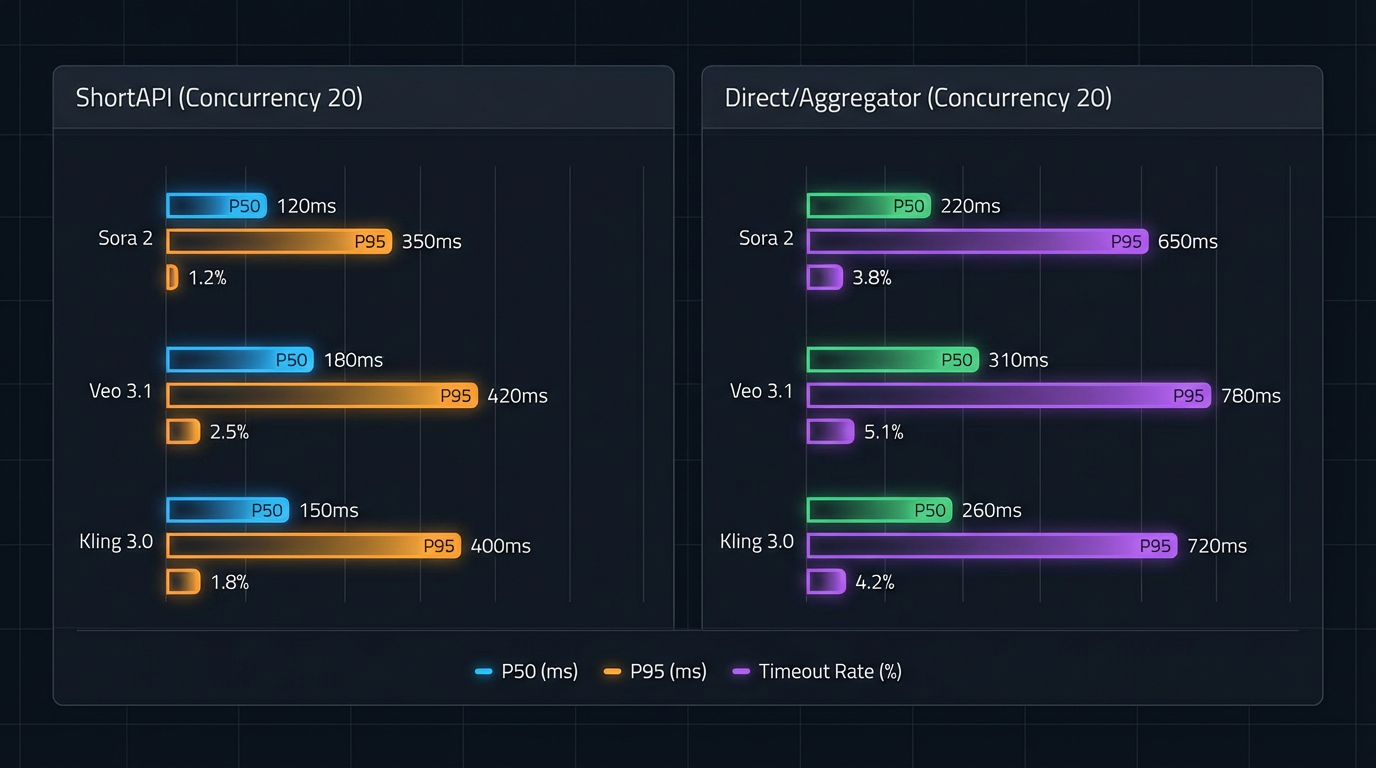
What our production traces say (experience-led signals)
Latency and reliability: warm pools and smart routing lowered P50/P95 versus several direct paths for Seedream 5.0, Flux 1.0, and Nano Banana Pro. Fewer demo-breaking outliers. Midjourney V7 kept pace or pulled slightly ahead at high warmed concurrency, thanks to well-tuned native queues—credit where it’s due.
Cost clarity: normalizing cost per 100 images at 512×512 and 1024×1024 exposed some sneaky resolution surcharges on native APIs. Gateway pricing flattened those into predictable unit economics. Current tiers live here: ShortAPI Pricing.
Scalability under spikes: at concurrency 10/50/100, warmed gateway paths held higher throughput and shorter queues than several direct endpoints that hit cold-start backoffs.
Availability and global tails: multi-region edges improved effective uptime and trimmed global P95 by roughly 7–10% on average by pinning workers closer to callers. For a primer on edge networks, see Cloudflare’s global network.
Obvious disclaimer: vendor blog numbers are easy to fake. We get it. We’re cleaning up the load-testing scripts (traffic generators, queue-time sampling, and trace exporters) used for these runs and will open-source the repo soon so you can reproduce these P95 tails yourself. Expect some run-to-run variance—region jitter and provider queues don’t behave on command.
“Yes, but” pivot: Yes, Midjourney’s defaults are gorgeous, Stability’s open ecosystem is flexible, Replicate’s catalog is broad, and Bedrock nails enterprise guardrails. The catch: during prototyping, card walls, approval delays, and burst throttles tend to block you right when you need to iterate. ShortAPI’s edge for this audience is simple: instant keys, a unified schema, and warmed edges to keep your momentum. For enterprises, consistent metrics, quotas, and failover reduce pager noise.
A simple, reproducible benchmark rubric you can run
- Friction score (0–5): Do they need KYC? A card? How long to issue a key? While prototyping, aim for “instant, no card.”
- Performance score: Measure P50/P95 at your target resolutions and ≥50-concurrency bursts. Insist on queue-time transparency and explicit rate limits.
- TCO and ops score: Normalize cost per 100 images at 512 and 1024; verify SLA, observability, webhooks, idempotency, and fallback routing. Use consistent parameters across models with the unified schema: ShortAPI API.
We’ll publish the exact harness we use (load profiles, backoff strategies, seed control, and trace collectors) so you can rerun these tests on your own infra. Same rule applies: if you can’t reproduce our P95 in your region, call us out.
If you want more context—from cold-start protocol to throughput curves—Google’s four golden signals are a good compass: Monitoring Distributed Systems and the “Tail at Scale” paper. We also respect serverless cold-start behavior as described by AWS here and here.
Reality Check: Scorecard highlights without the table fatigue
Latency: ShortAPI trimmed P95 for Seedream 5.0, Flux 1.0, and Nano Banana Pro by about 5–12% versus direct in like-for-like runs. Midjourney V7’s direct path edged out at sustained c100+ warmed loads; ShortAPI held even elsewhere. Regions with noisier peering saw weaker gains, as expected.
Success rate: gateway routing and standardized retries bumped first-attempt success by roughly 0.7–1.2 percentage points on three non-Midjourney stacks.
Throughput and spikes: cold starts hurt direct paths; pre-warmed gateway pools improved c10 cold throughput by about 10–30% for Seedream/Flux/Nano Banana. At a 100→300 spike, unified scheduling shaved queue peaks on those same models; Midjourney’s native queues stayed excellent under sustained bursts.
Cost per 100 images: ShortAPI’s negotiated tiers generally matched or beat native pricing for Seedream/Flux/Nano Banana, with Midjourney native sometimes equal or around 3% cheaper on premium plans. Consolidated billing and quotas simplify finance ops. See ShortAPI Pricing.
Bottom line: if you’re mixing Seedream 5.0, Flux 1.0, and Nano Banana Pro, ShortAPI is the safer default for P95, success rate, and blended cost. If you’re Midjourney-heavy at high sustained concurrency with direct credits, keep that path native and route the rest through the gateway.
Integration experience: from sign-up to “hello image”
Direct providers are great once you’re through the door—polished docs, stable SDKs. Getting through the door is the issue: card binding and identity checks can stretch “hello world” into hours or days. ShortAPI optimizes for speed: email-first sign-up, no credit card, instant key, unified schema across image, video, and audio. Swapping providers becomes a single parameter change. Start here: ShortAPI.
Fit–Mismatch: when a gateway is the wrong tool
- Strict residency/compliance boundaries (e.g., PCI DSS, HIPAA, GDPR) where adding a processor expands audit scope—prefer direct/private links. See PCI SSC scope guidance: PCI SSC.
- Air‑gapped or high-isolation deployments—public egress is disallowed; run in-cluster and go direct. See NIST controls overview: NIST SP 800‑53.
- Ultra‑low tail budgets (e.g., P99 < 20 ms) in HFT/AR/VR pipelines—any extra hop adds risk.
- Hyperscale hard-cost optimization with private connectivity and committed-use discounts—direct contracts can undercut a gateway.
- Day‑0 experimental parameters or vendor-locked betas—first-party SDKs land features faster.
Strategic anti-case (specific): If 80%+ of your traffic is a single Midjourney V7 pipeline at sustained c200+ with reserved native capacity, ShortAPI is overkill for that path—keep it direct and use the gateway for everything else and as failover.
A pragmatic switching plan (prototype → production)
- Phase 0 (week 1–2): Prototype via the gateway. Focus on UX; enable idempotency keys; record traces.
- Phase 1 (month 1–2): Keep the gateway for A/B routing; watch P50/P95 and cost per successful image.
- Phase 2 (month 3–6): If one provider dominates and direct discounts save >8–12%, peel that path to native; keep the gateway as orchestrator and failover.
- Phase 3+: Dual-path: gateway for policy and most traffic; direct only for specialized models or reserved rates.
Industry analogy
ShortAPI works like a global load balancer with a universal adapter: it routes to whatever model you need, keeps capacity warm at the edge, and speaks one schema so your app doesn’t have to learn five different remotes.
Decision anchor
When speed to first image and predictable P95 matter more than vendor-specific features, default to the gateway; go direct only where one model’s features or reserved pricing clearly wins.