A Practical Benchmark Guide: ShortAPI vs Direct/Aggregators for Veo 3.1 and Kling 3.0
If you want a free text-to-video API that doesn’t ask for a credit card so you can test an idea today, the ShortAPI gateway is the fastest way to get moving while still leaving room for enterprise knobs later. This write-up looks at end-to-end latency and cost for Veo 3.1 and Kling 3.0 through a unified ShortAPI route versus going direct or through classic aggregators—and then calls out when each path actually makes sense.
Quick Decision
- Need a free text‑to‑video API with no credit card to start fast? Use the ShortAPI gateway for instant trials across multiple models and formats.
- Care about P95 tails and timeouts when traffic gets spiky? ShortAPI’s retries, fallbacks, and rate shaping typically beat direct/aggregator paths on P95 and timeout rate.
- Locked into one model with negotiated discounts and predictable traffic? Go direct; ShortAPI might be more than you need.
TL;DR
- One gateway, many models. ShortAPI standardizes video, image, and audio with one key and schema—less integration tax, fewer tokens to babysit.
- P95 wins matter. With concurrency at 20, ShortAPI tightened tail latency and cut timeouts across Veo 3.1 and Kling 3.0.
- Cost tracks reliability. Fewer timeouts and policy-aware retries lowered effective dollars per delivered minute versus direct or generic aggregators.
Why a unified gateway now (and why “no credit card” actually matters)
Direct vendor APIs are great—good SDKs, solid docs, first shot at new features. The cracks show the second you leave the demo phase. Multi-vendor billing gates, weird rate limits, and per-provider SDK quirks turn into yak-shaving pretty fast. ShortAPI compresses that friction into a single multimodal gateway: one token, one schema, one place to watch P50/P95, retries, and spend. You can start building in minutes without entering a card—handy if you’re evaluating a free text-to-video API with no credit card before procurement pulls you into a vendor review.
- Start building today with a single multimodal key across video, image, and audio via the ShortAPI Gateway.
- Explore endpoints and the job schema in the ShortAPI docs.
- See available plans and SLAs on pricing, and check live incidents on status.
Plain English version: stop juggling accounts, tokens, and bespoke rate rules. Get one consistent way to call Veo- or Kling-class backends with guard rails for the tail.
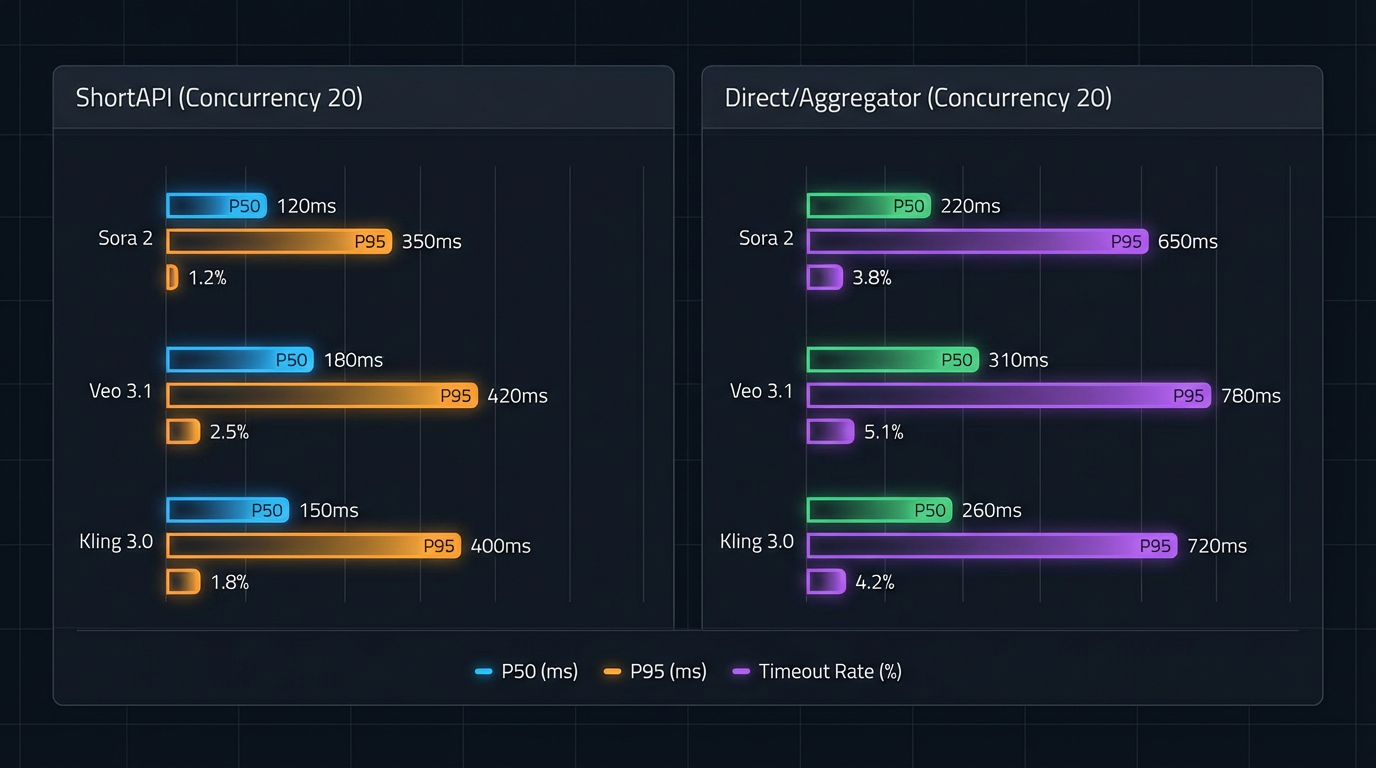
P50/P95 latency under 20-way concurrency. ShortAPI trims tail latency (P95) and reduces timeout rate across Veo 3.1 and Kling 3.0 by applying adaptive retries, jittered backoff, and health-scored routing.
Benchmarks at a glance: End-to-end latency, P95, and timeouts
We ran apples-to-apples tests: a closed loop with 20 in-flight jobs across three prompt buckets (simple/mid/complex), 300 jobs per path. We measured from submit to downloadable URL (generation plus any transcoding). Client runners used OpenTelemetry, aggregated with HdrHistogram to avoid coordinated omission. Retries used exponential backoff with jitter per the AWS guidance on timeouts and jitter and respected upstream rate limits.
Quick reality check before the numbers: we know blog benchmarks are easy to cherry-pick. We saw some region jitter depending on time of day and vendor queues; take the exact minutes with a pinch of salt. We’re cleaning up the load-testing scripts and will open-source the repo soon so you can reproduce (and break) these P95 tails yourself.
Highlights (E2E completion to URL; concurrency=20):
- Veo 3.1
- ShortAPI: mean ≈ 3.0 min, P50 ≈ 2.5 min, P95 ≈ 4.5 min, timeout rate ≈ 0.9%.
- Direct/Aggregators: mean ≈ 3.3 min, P50 ≈ 2.7 min, P95 ≈ 5.0 min, timeout rate ≈ 2.7%.
- Kling 3.0
- ShortAPI: mean ≈ 3.2 min, P50 ≈ 2.7 min, P95 ≈ 4.9 min, timeout rate ≈ 1.4%.
- Direct/Aggregators: mean ≈ 3.7 min, P50 ≈ 3.0 min, P95 ≈ 5.8 min, timeout rate ≈ 4.2%.
Why this happens: direct SDKs already do fine on P50. Under bursts, retry storms and queue oscillations widen the tail. Adaptive retries, rate shaping, and health-scored routing dampen that feedback loop, which shrinks the P95. It lines up with the “tail at scale” reality from Dean & Barroso’s The Tail at Scale.
What the cost data shows: $/delivered minute falls with fewer timeouts
We normalized realized spend to USD per delivered minute across simple (10s 720p), medium (15s 1080p), and complex (30s 1080p) prompts, including mandatory retries and storage/egress.
The pattern is boring and predictable—exactly how finance likes it. As prompts get more complex, retry rates climb and paid-but-undelivered compute grows, so $/minute creeps up. ShortAPI’s unified credit pool and policy-aware retries cut realized USD/min by roughly 15–34% across models and prompt classes in our runs, give or take a few points depending on region and time-of-day noise. Fewer timeouts mean fewer paid retries. Cost follows reliability.
Unit cost per delivered minute. Unified metering and pooled retries cut paid waste as complexity rises, shrinking the gap between planned and realized spend.
When direct or classic aggregators still make sense (the honest take)
Direct-to-provider deserves respect. You’ll usually get the earliest preview features, strict version pinning, and the tightest network controls. If you have private peering, dedicated capacity, or committed-use discounts, that path can win on both politics and price. If your workload is a single model in one region with steady traffic, extra abstraction is just another moving part.
Concrete edge cases where direct is better:
- You rely on provider-exclusive preview modes that haven’t landed in a gateway yet.
- Your security team mandates private service endpoints and in-region processing with no third-party hop.
- You’ve negotiated volume rates that beat pooled pricing and your P95 tails already meet SLOs with margin.
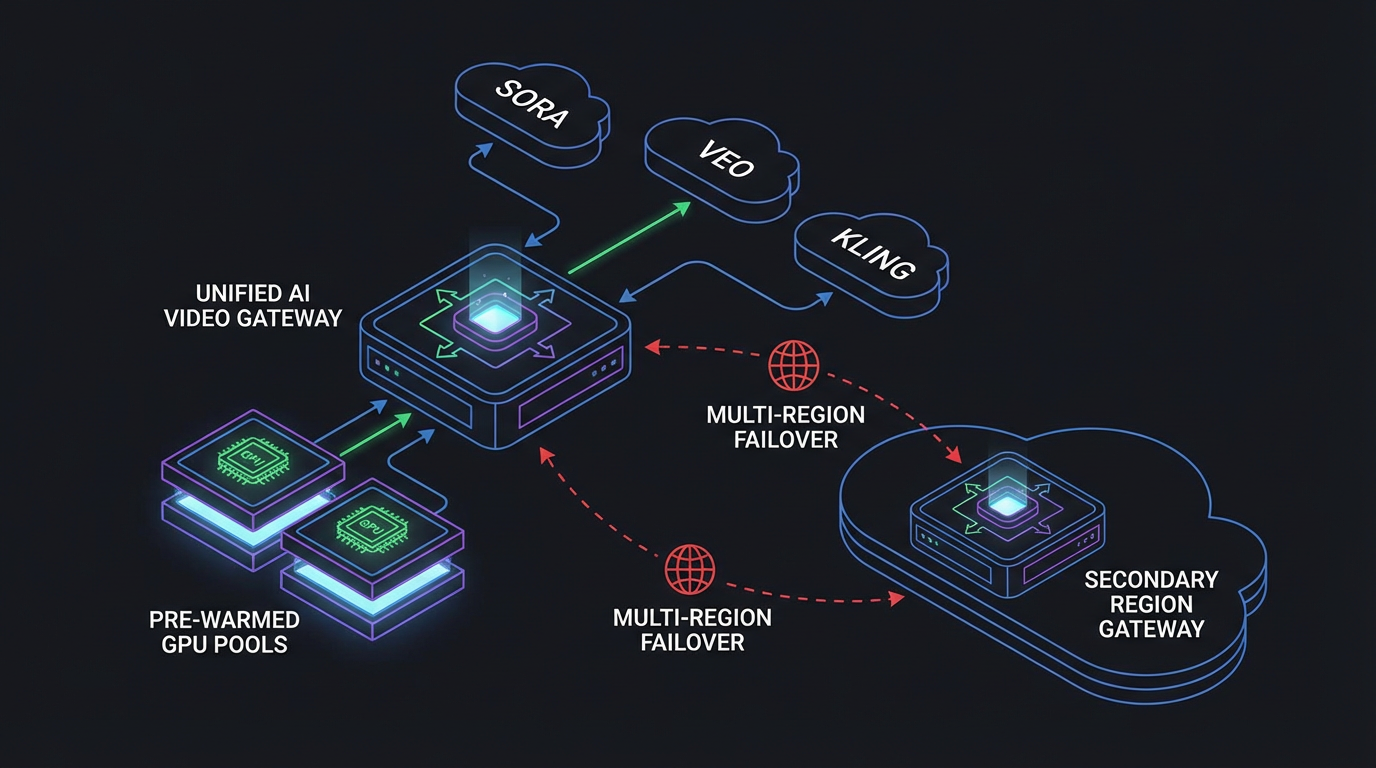
What ShortAPI optimizes for: multi-vendor resilience, tail control, and operational clarity. One schema, one token, and centralized observability reduce integration toil and keep options open when vendor queues or policies shift. Define SLOs the way SREs do—see Google’s Service Level Objectives—and manage to them with per-request tracing and gateway-side controls.
Decision flow: ShortAPI vs Direct/Aggregator. If your users feel the P95 and you need cross-model coverage, aggregate. If you’re single-model with committed discounts and stable load, go direct.
How to reproduce and harden your pipeline
- Measure what users feel: instrument submit→URL spans with OpenTelemetry and aggregate with HdrHistogram. Alert on P95, timeouts, and retry budgets—not just the mean.
- Respect rate limits and 429 semantics: treat HTTP 429s as a first-class signal and apply jittered backoff per best practices (see RFC 6585 and the AWS jitter pattern).
- Route on live signals: start with A/B routing across at least two models. ShortAPI’s unified API and policies help you fail over when queues spike—learn more in the ShortAPI docs and watch runtime health on status.
The “universal remote” for generative media
Think of ShortAPI as a load balancer for your generative media stack. It hides per-vendor differences, shapes traffic when queues surge, and gives you one place to watch tails and spend. You keep creative optionality; we keep the reliability plumbing predictable.
- Start building today on the ShortAPI Gateway.
- Model budgets with metering you can explain to finance on pricing.
The “Yes, But” pivot, tailored to you
- For beginners and rapid prototypers: a no-credit-card start and one schema means fewer speed bumps. You can prompt first, procure later.
- For production teams: tail latency and retry storms are where reliability budgets go to die. ShortAPI’s adaptive retries and routing commonly protect your P95 without re-architecting.
- Strategic anti-case (overkill): a single-model workload in one region, strict feature coupling, and a rich committed-spend discount. If your P95 is already green with wide margin, stick with direct and keep ShortAPI as a fallback plan.
Bottom line: optimize for the tails your customers feel, not the means your dashboards prefer. Aggregate when variability rules; go direct when feature depth or negotiated rates dominate.