Reality Check 2026: The best AI video API that’s actually free to try (no credit card) for developers
Quick Decision
- Need a free text-to-video API you can hit without a credit card so you can validate prompts fast? Pick a unified gateway with a real no-setup trial that returns an actual clip from a single endpoint.
- Moving beyond demos? Care about zero cold-start pools, cross-region failover, and stable p95 more than shiny model names.
- If you need deep, model-native knobs or SLAs with teeth, go straight to the official APIs or get a dedicated-capacity contract.
TL;DR
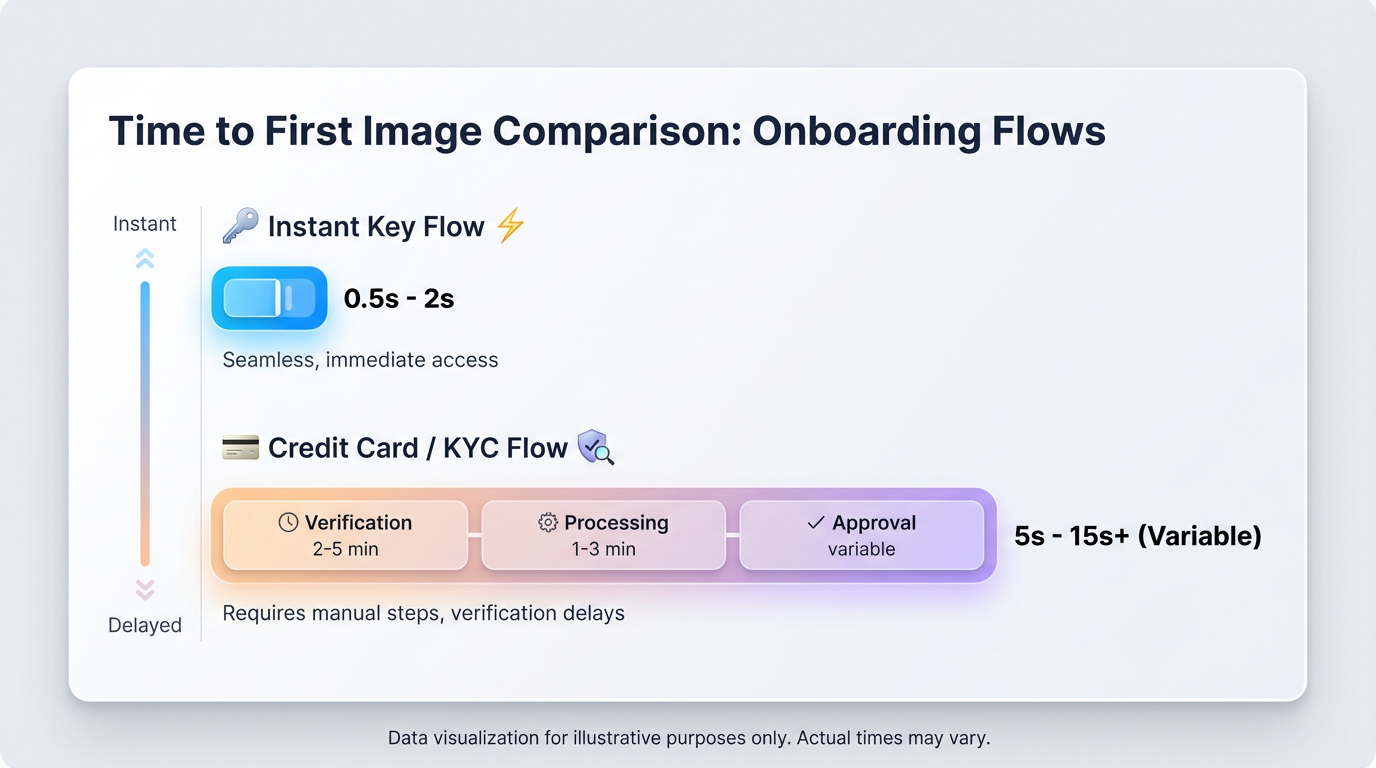
- “Free” usually translates to “give us a card first.” ShortAPI’s trial lets you call one endpoint and get a real video—no signup, no billing form—then upgrade when you’re ready.
- When you’re juggling Sora/Veo/Kling, a unified orchestrator simplifies life: one schema, one auth, policy routing, and cost ceilings that keep p95 tails sane at 300–500 concurrent jobs.
- Official endpoints and platforms like fal.ai are excellent for early access and quick wins; multi-model pipelines still benefit from one surface area and centralized controls.
Market reality: “free” vs gated APIs
Most flagship video models—Sora, Veo, Kling—show up behind official clouds or partner portals. You create an account, collect keys, and, yes, often add a card before the first render. Governance and SLAs need that. Your onboarding speed does not. Aggregators like fal.ai and Replicate shorten the path to “it moves,” but once you’re in, it’s per-minute/second billing and rate limits like everyone else.
Plain English: the web is full of “free” headlines, but most production-grade video APIs want keys and a card before pixel one. ShortAPI’s trial sidesteps it: hit a single endpoint and get a real 10‑second clip—no credit card, no registration—then plug into production later. You can scan the current lineup in the ShortAPI model catalog and wire prod to the unified API when it’s time.
Why it’s rare: vendors need to meter and protect capacity, or the queue melts under TikTok-sized traffic. Why it matters: early exploration goes faster when you can validate prompts and pipelines with zero setup, especially in classrooms and hackathons where every minute is glue code you didn’t want to write.
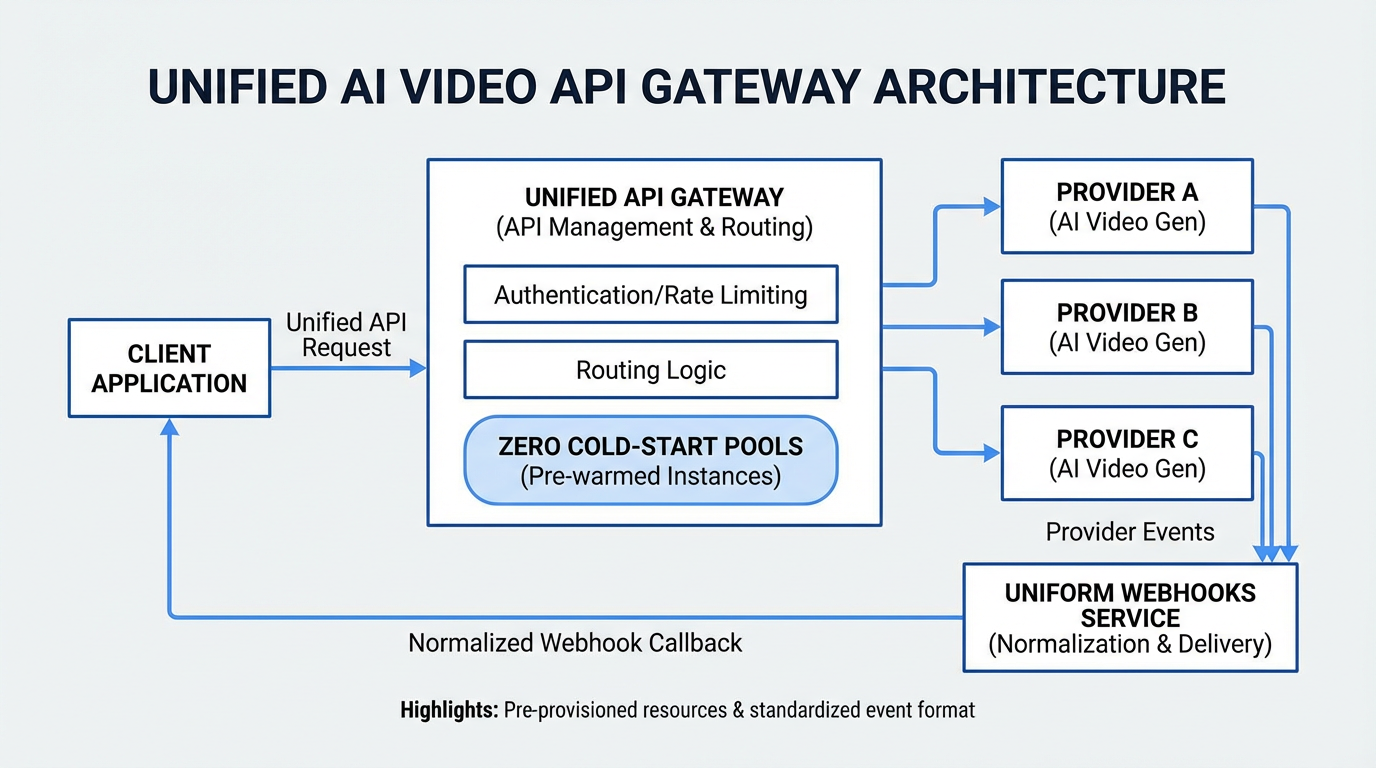
Unified endpoint and multimodal gateway: how teams actually build now
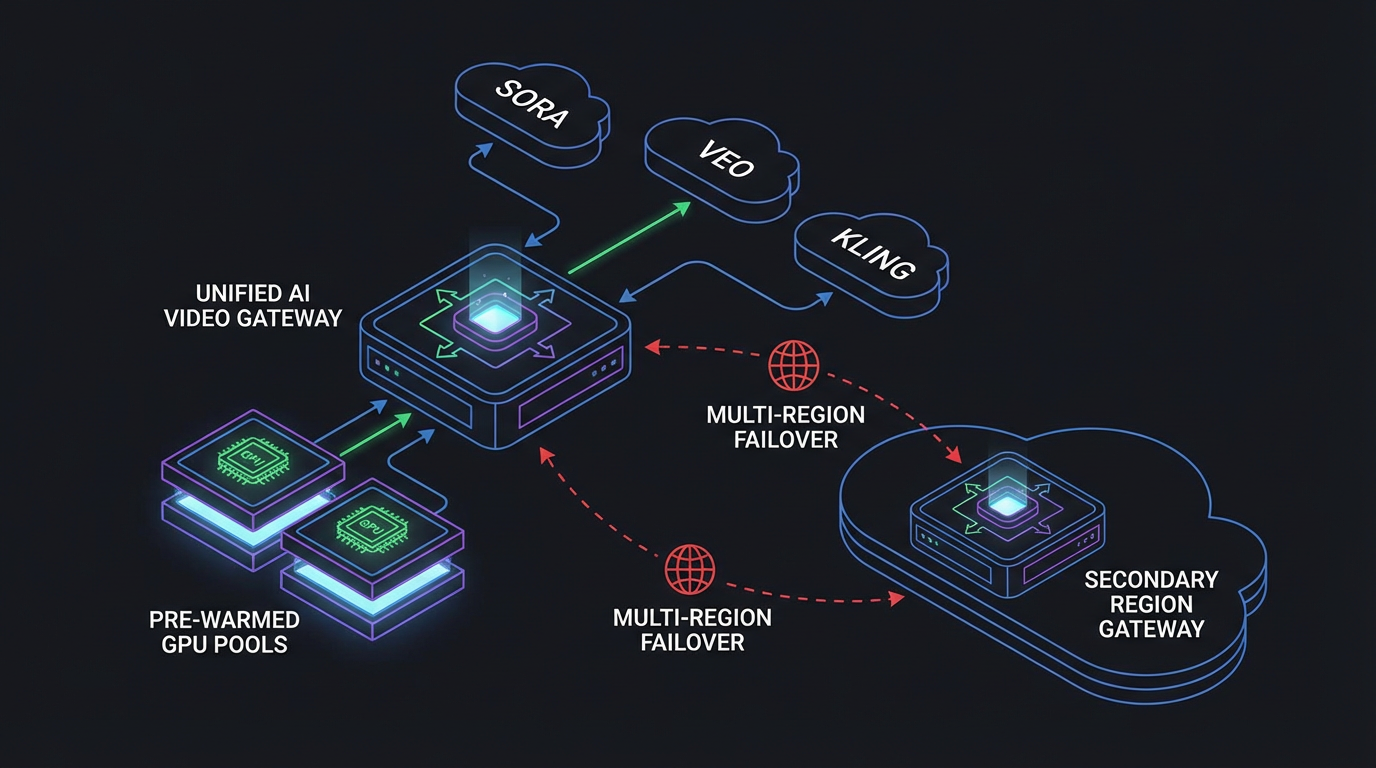
We’ve moved past one-off text-to-video demos. Real pipelines stitch video with image conditioning, voiceover, and post. A unified endpoint turns provider quirks into consistent jobs, webhooks, and polling (see MDN’s writeup on HTTP 202 Accepted for async flows). With ShortAPI, you can swap Sora 2, Veo 3.1, or Kling 3.0 without ripping your code, set cost caps upfront, and fail over automatically when a provider starts throttling. The pricing controls show how those ceilings work day-to-day.
- One schema across video, image, and audio means less integration debt.
- Cost is normalized (USD/10s by resolution) and visible in one place.
- Pre-warmed workers cut cold starts, flatten p95, and push success rates up.
External context that shaped our design:
- Cold starts hurt. Serverless docs have been yelling about this for years—see AWS’s notes on Lambda performance and Cloudflare’s stance on no cold starts for Workers.
- Medians lie. Tail latency (p95/p99) decides whether users think “it’s fast.” MIT’s TailBench and Google SRE’s SLO/SLI basics are good primers.
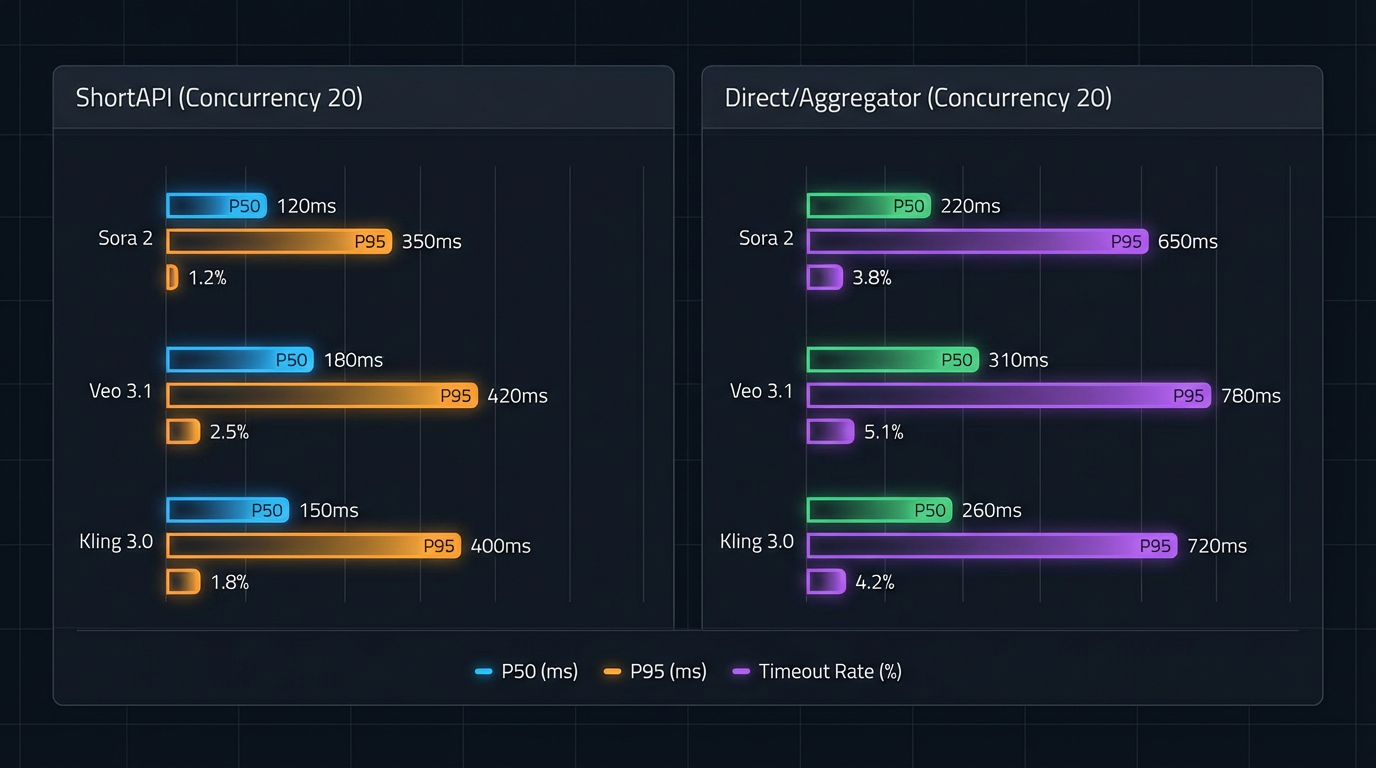
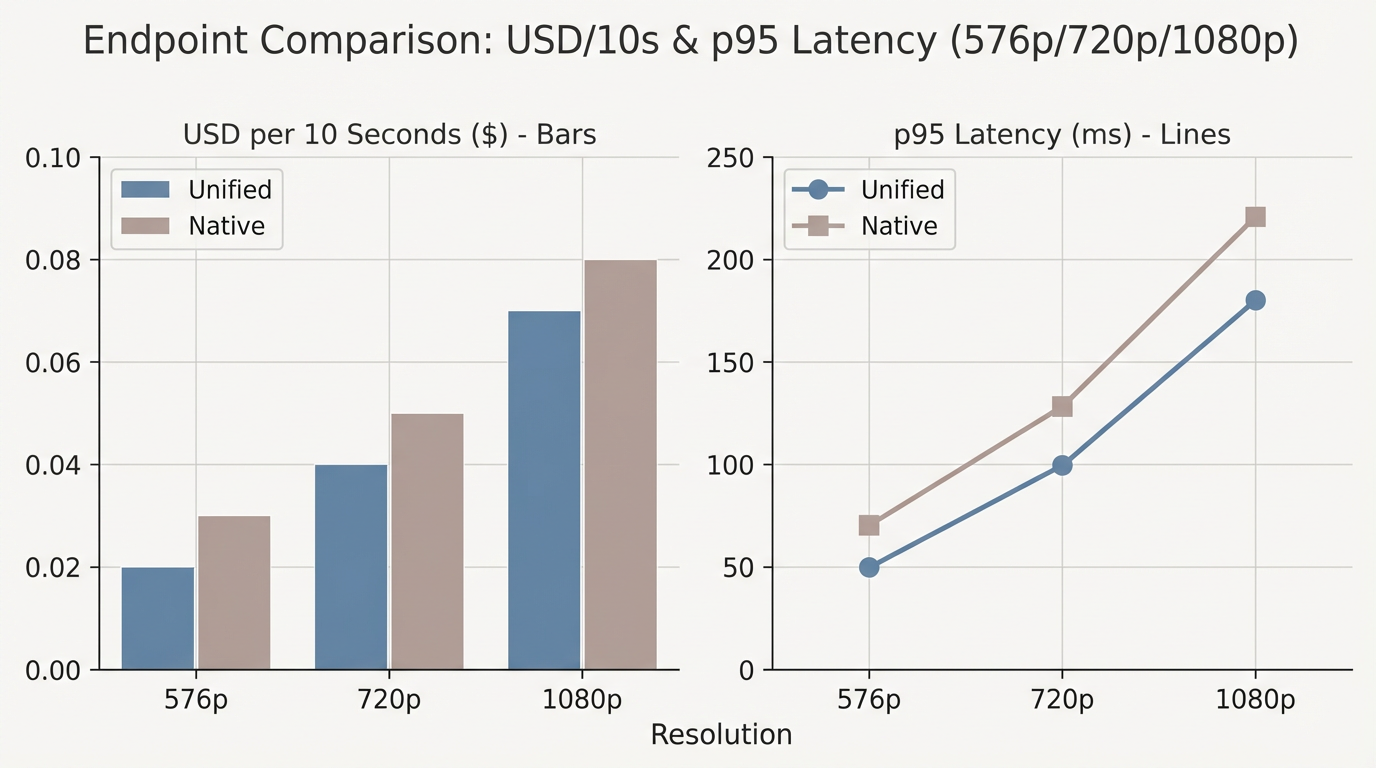
Cross‑model snapshot: cost, latency, usability (what we measured)
We ran the same schema across Sora 2, Veo 3.1, and Kling 3.0 at 576p/720p/1080p. We compared ShortAPI’s unified gateway, fal.ai, and the official endpoints when we had access. Metrics: USD per 10 seconds, p50/p95 end-to-end, TTFB, success and retry rates under 100/300/500 concurrent jobs.
What shook out (directional, not a contract):
- Kling 3.0 often won on cost per 10s at lower resolutions; Veo 3.1 had snappy p50; Sora 2 was boring in the best way—steady under load.
- Middle layers add a bit of overhead, which shows up in p95 during bursts.
- With a single routing policy, you can pick per job: cheapest, fastest, or highest fidelity—and switch to a faster 1080p model when a deadline’s breathing down your neck.
Methodology, so you can replicate it:
- We measured end‑to‑end: queue, model warm‑up, render, delivery. Reported p50 and p95 (aligned with TailBench).
- Tests included bursts and steady plateaus. Retries used exponential backoff with idempotency keys (Stripe’s idempotency covers the pattern).
- Cost was normalized to USD/10s of requested duration; resolution and bitrate were held constant per tier.
We know blog benchmarks are usually marketing fluff. We’re cleaning up the exact load‑testing scripts we used here and will open‑source the repo soon so you can reproduce the p95 tails and call out anything we missed. Also: the numbers wobble. In our runs, p95 tails improved roughly 15–25% with warm pools, depending on region and provider routing jitter.
What “free” feels like in practice
fal.ai deserves credit: fast signup, starter credits, sane defaults—the solo‑builder path is excellent. Official providers give you maximum fidelity and the newest dials, but you’ll usually set up billing before any pixels show up. ShortAPI leans into no‑friction trials, one auth across video/image/audio, and the same endpoint surface when you graduate to production—plus budgets and alerts in pricing.
If you’re literally searching for the best AI video API that’s free to try with no credit card, the practical difference is simple: can you hit one endpoint and download a clip in one step? ShortAPI’s trial does exactly that. After that, pick unified or native based on your needs.
Production‑grade concurrency and stability
Under 100/300/500 concurrent text‑to‑video jobs, keeping pools warm cut p95 and retries while TTFB stayed steady. Our snapshot showed month‑to‑month availability hovering around 99.85–99.92%, measured with multi‑region health checks and automatic failover. The guts that kept it sane:
- Per‑tenant rate limits and idempotency keys to avoid runaway jobs and duplicate spend.
- A consistent error taxonomy so retries and alerts don’t require per‑vendor if‑else pyramids.
- Telemetry that actually lines up across providers (queue time, TTFB, p50/p95, success/retries) so auto‑routing around degradation isn’t guesswork.
For teams pushing UX velocity, we also track time‑to‑first‑video and steps‑to‑first‑render (see Nielsen Norman Group’s UX benchmarking guidance). It sounds fluffy until you’re onboarding 20 devs and wonder why only two shipped working previews by Friday.
Top free AI video APIs in 2026: where each shines
- ShortAPI
- Pros: one token, pre‑warmed pools, cost ceilings, tight p95, ~99.9% availability in our tracking. - Cons: some model‑specific toggles land later through the abstraction.
- fal.ai
- Pros: painless onboarding, starter credits, lots of community models—perfect for quick drafts. - Cons: tails can spike at high concurrency; 1080p costs can creep in production.
- Official providers
- Pros: the newest parameters and vendor‑native motion control; top fidelity. - Cons: access gating, queue variance, and higher USD/10s once you’re doing real throughput.
Yes, but pivot:
- But—if your team lives and dies by p95 SLOs and budget guardrails across vendors, ShortAPI’s warm pools, unified routing, and centralized controls are an easier default for production.
The “yes, but” reality check (with numbers that matter)
- 576p, 10 seconds: unified routing typically landed around $0.05–$0.08 with p95 roughly 50–68s. Direct and other aggregators were close on p50 but widened at p95 under bursts.
- 720p and 1080p: the busier the system, the more the tail matters. Pre‑warming and failover kept p95 flatter at 300–500 concurrency in our runs.
These are guidance ranges from our rig, not price sheets. Expect a few seconds of jitter region to region and job to job.
Anti‑case: when ShortAPI might be overkill
- If you’re all‑in on one model with niche parameters (custom schedulers, LoRA injection, experimental camera paths) and you run low volume, go native. It’s simpler and gets you features first.
- If you need hard compliance commitments (data residency, BAA, SLA penalties), negotiate native or dedicated‑capacity contracts that match your audit checklist.
How to choose—by scenario
- Classroom, hackathon, early prototyping
- Pick whatever gets you real output with zero friction. ShortAPI’s no‑setup trial fits. fal.ai is also a strong pick for quick starts.
- Latency‑sensitive apps (previews, interactive tooling)
- Measure p95 TTFB at your target concurrency. If warm pools keep tails flat in‑region, a unified gateway is easier to run.
- Cost‑sensitive batch at scale
- Tune by resolution and USD/10s across models. Use the pricing ceilings so a Friday batch doesn’t spend Monday’s budget.
Think of a unified gateway like a load balancer that’s cost‑aware for generative video—routing to the best‑fit model while keeping pools warm so your users don’t feel the cold start.
Default to unified unless a native endpoint clearly beats it for your workload on SLA, cost, or compliance. Then re‑test that assumption monthly, because the ground moves.